Abstract Syntax Trees
1. Introduction
I have proposed moving from PAXIX’s current style of direct code generation to an AST based model. The AST model has a number of advantages over our current method. I will first explain a little about the advantages we will gain, then discuss how such a system could best be implemented.
2. Advantages
2.1. Optimization
The first advantage, and the one which I cannot give examples of, is the ability to optimize the code generated by our compiler. The PAXIC currently does not have any kind of intermediate representation. Our ability to perform operations on the generated source code is limited. It would require another parser to read the generated machine code and re order the instructions.
2.2. Multiple Pass Compilation
The most evident of the advantages gained with this architecture shift is the ability to pass over the program to be compiled multiple times. For instance, we can add all procedure entries to the symbol table before they need to be checked. The given paxi program results in a compilation error:
proc main()
foo()
bar()
endproc
proc foo()
writestr("Hello ");
endproc
proc bar()
writestr("World!");
line;
endproc
This is because foo() and bar() are called before they are defined. PAXIX,
much like C, currently requires methods to be defined before use. However, this
isn’t a necessary handicap. This program could be represented with this syntax
tree:
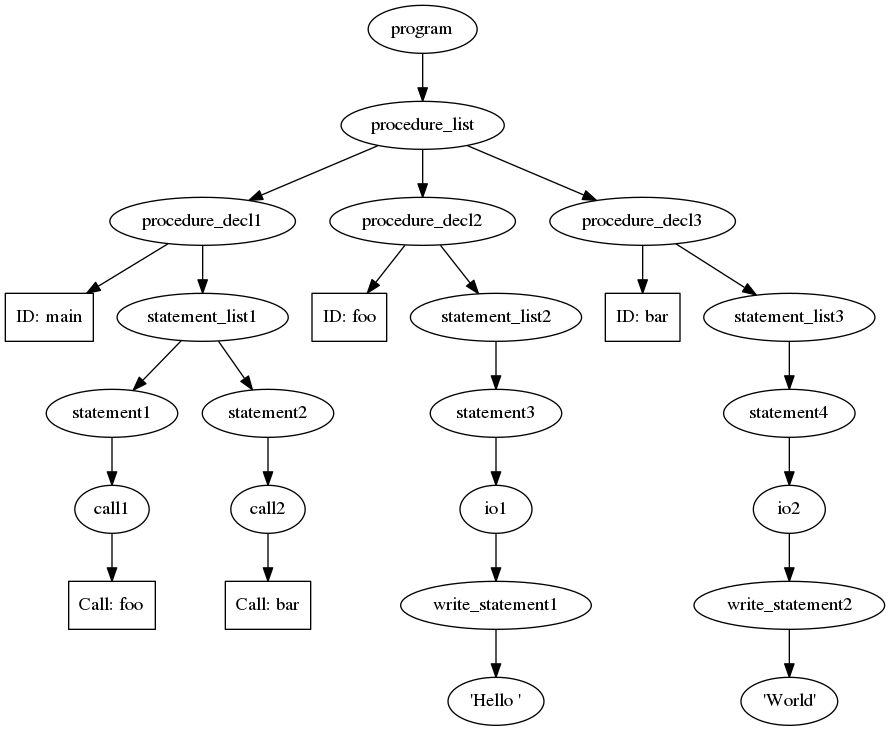
Once the program is represented as a tree, it is easy to traverse the tree as
far as the procedure_decl nodes. These nodes can be parsed to add their
information to the symbol table. The next compilation pass can work with the
knowledge that all of the procedures that can be called are already present in
the symbol table1.
2.3. PAXIX Modularity
Currently, there PAXIX has no module concept. Any code that is going to be used
by the program must be written into the program itself. This is the reason for
the <io> production. This is a kludge that served well enough for a learning
exercise, but will have to be replaced sooner or later in the expansion. The
current implementation would require us to have some kind of proto-type or
dummy procedures that could be left empty and replaced by the linker later.
With a syntax tree, this limitation is removed. Compiling multiple source files is greatly simplified by creating a unified syntax tree. As long as their is only one entry point, there is no need for a messy header system to keep imported source files organized2.
With these problems solved, the only remaining modularity issue to solve will be loading files that cannot be representing in PAXIX. Some standard library procedures will have to be implemented directly in assembly. We will have to devise another kind of scanner that can load these and add them either to the syntax tree or directly to the symbol table.
3. Implementation
3.1. Data Structure
Bison maintains an implicit syntax tree. We need to have an explicit one in order to traverse it effectively. The best way to do that is through a tree made of linked structs. There are 3 different implementations that would achieve our requirements. All of these implemenations require a struct for each of the productions that will appear in the AST.
3.1.1. C Polymorphism
A fairly common design pattern it is possible to make “substructs” in C. Our base implementation might look like this:
typedef struct{
ast_node** children;
} ast_node;
typedef struct{
ast_node base;
char* id;
} ast_procedure_decl_node;
This structure has the benefit of allowing us to use the base ast_node whenever we need it. The drawback to this system is that there will be lots of casting and it may be harder to make sure that our nodes are the correct type when we want them to be.
3.1.2. Seperate structs
The second possible implementation requires a unique struct for each of the productions in the language, and specific naming of the children for each node:
typedef struct{
ast_node_globals_list* globals_list;
ast_node_procedure_list* procedure_list;
} ast_node_program;
typedef struct{
ast_node_globals_decl** globals_decls;
} ast_node_globals_list;
This implemementation is useful because our C functions can call on the specific kind of struct we are using, and because we can guarantee the values that our structs are going to have.
3.1.3. Other
The third option is probably the least appealing, and so I will only mention it briefly. Given a single kind of struct with an enum field we can check the type of node at run time by comparing the enum values.
3.2. Creating the tree
Currently, our parser generates raw PVM assembly:
quantity: variable{
emit(27, 500, 0);
emit(3, 500, 500);
emit(24, 500, 0);
}
...
variable: ID_TOKEN{
...
}
When generating an AST we will instead generate nodes and pass them back up the tree to be attached at a later point:
quantity: variable{
ast_quantity_node* new = malloc(sizeof(ast_quantity_node));
new -> variable = $1;
$$ = new;
}
...
variable: ID_TOKEN{
ast_variable_node* new = malloc(sizeof(ast_variable_node));
new -> id = $<sval>1
$$ = new;
}
This way, by the time we get back up to the <program> production, we will
wind up returning a pointer to the root node for the whole tree.
3.3. Generating Code
Once the AST has been generated, creating code from it is as easy as doing a tree traversal. Each unit of the tree can be cleanly subdivided into it’s component nodes. The globals list can be be generated one node at a time, and then the functions list. Generation will move the emitting of instructions out of the parser and into an outside module. For the most part the code generation will be the same:
generate_quantity(ast_quantity_node* node){
if(node -> variable != null){
printf("Load variable address");
printf("Load variable value");
printf("Push variable on stack");
} else if (node -> call != null){
generate-call(node -> call);
} else if (node -> int != null){
printf("Push node -> int to stack");
} else if (node -> char != null){
printf("Push node -> char to stack");
}
}
-
Paxi currently requires a location for procedure calls, while switching to amd64, this will no longer be necessary: jumps can be to labels instead of memory locations. ↩
-
As an aside, the easiest way to accomplish this is to hijack the C preprocessor. We can use it to simply paste other source files at the top of a paxix source, and use then compile the resulting text. ↩